
区块链上的数据究竟是如何存储的?分布式节点如何共同维护数据一致性?
 摘要:
将数据打包成“区块”(Block),然后通过密码学方法将这些区块按时间顺序链接成一条不可篡改的“链”(Chain),下面我们从几个层面来详细拆解这个过程:核心思想:去中心化的分布式...
摘要:
将数据打包成“区块”(Block),然后通过密码学方法将这些区块按时间顺序链接成一条不可篡改的“链”(Chain),下面我们从几个层面来详细拆解这个过程:核心思想:去中心化的分布式... 将数据打包成“区块”(Block),然后通过密码学方法将这些区块按时间顺序链接成一条不可篡改的“链”(Chain)。
下面我们从几个层面来详细拆解这个过程:
(图片来源网络,侵删)
核心思想:去中心化的分布式账本
要理解区块链存储的不是单个文件或数据库,而是一个“分布式账本”(Distributed Ledger)。
- 传统数据库:数据存储在中心化的服务器上,你在银行的钱,数据存在银行自己的数据库里,银行可以修改、删除这些数据。
- 区块链:数据被复制并存储在网络中成千上万个节点(计算机)上,每个节点都保存着从创世区块开始到当前最新区块的完整账本副本。
这种分布式存储带来了几个关键特性:
- 高可用性:单个节点宕机或损坏,不会影响整个网络的数据,只要网络中还有其他节点存活,数据就不会丢失。
- 防篡改:要篡改数据,攻击者需要同时修改网络中超过51%的节点上的数据,这在大型公链(如比特币、以太坊)上是几乎不可能完成的任务,成本极高。
- 透明性:在公有链上,任何人都可以查看整个账本上的所有交易记录(虽然地址可能是匿名的)。
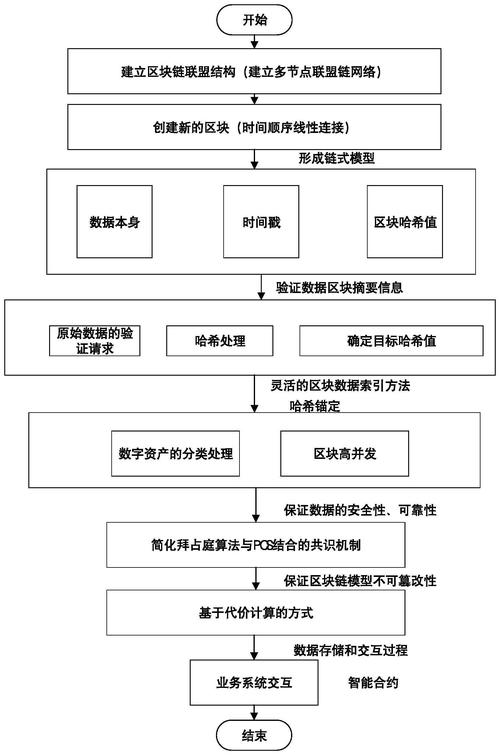
数据是如何被打包成“区块”的?
一个区块是数据存储的基本单元,它主要由两部分组成:
区块头 - 存储元数据和指纹
这部分是区块的“身份证”,包含了验证区块完整性和链接到前一个区块所需的关键信息。

(图片来源网络,侵删)
- 前一个区块的哈希值:这是最重要的部分,它通过加密哈希函数(如SHA-256)对前一个区块的所有内容(包括区块头和区块体)进行计算得出的一个独一无二的“指纹”,这就形成了一个链条,每个区块都指向前一个,确保了顺序的不可更改性。
- Merkle 树根哈希:这是对区块体内所有交易数据的“指纹”,它将所有交易的哈希值两两配对,再计算这对哈希值的哈希值,如此递归,最终得到一个顶部的根哈希,这使得验证一笔交易是否在区块中变得非常高效,无需下载整个区块。
- 时间戳:记录区块创建的大致时间。
- 随机数:也叫“Nonce”,是“工作量证明”(Proof of Work)机制中的关键参数,矿工通过不断尝试不同的随机数来寻找满足特定难度的哈希值,这个过程就是“挖矿”。
- 版本号:表示区块链协议的版本。
区块体 - 存储实际数据
这部分是区块的“身体”,存储了该区块包含的实际数据。
- 在 比特币 中,区块体主要存储的是交易列表,这些交易记录了谁转了多少钱给谁。
- 在 以太坊 中,区块体除了存储交易列表,还存储了状态变更记录和日志等更复杂的数据。
数据是如何写入“链”中的?(共识机制)
新的数据(交易)不能随意写入区块链,必须经过网络中所有节点共同认可的过程,这个过程就是共识机制。
以比特币的工作量证明为例:
- 广播交易:用户发起一笔交易,广播到整个网络。
- 打包交易:网络中的“矿工”节点收集大量的待确认交易,将它们打包成一个候选区块。
- 竞争记账权:矿工开始进行“挖矿”,即不断尝试不同的随机数,去计算候选区块头的哈希值,目标是找到一个哈希值,使其满足全网约定的难度要求(哈希值的前N位必须是0)。
- 广播新区块:第一个找到有效哈希值的矿工,将这个新区块广播给全网其他节点。
- 验证与确认:其他节点收到新区块后,会立即验证其有效性(特别是验证哈希值是否达标,以及交易是否合法),如果验证通过,大家就接受这个新区块,并将其链接到自己账本的末端。
- 获得奖励:成功记账的矿工会获得一定数量的新铸造的比特币和交易手续费作为奖励。
这个过程确保了只有经过全网算力竞争胜利的区块才能被添加到链上,从而保证了数据写入的安全性和有序性。
(图片来源网络,侵删)
不同区块链的存储策略(重要补充)
上面描述的是最基础的模式,但不同的区块链在存储“实际数据”时有不同的策略,这至关重要。
数据上链 vs. 数据链下
这是一个核心区别:
-
链上数据:指直接存储在区块体里的数据。
- 优点:安全性最高,由整个区块链网络共识和保护,不可篡改,永久存在。
- 缺点:成本极高(尤其是以太坊,每写入一个字节都需要支付Gas费),容量有限,效率较低。
- 适用场景:高价值、需要绝对信任、体量小的数据,如交易记录、资产所有权证明、合约代码等。
-
链下数据:指不直接存储在区块链上,而是存储在传统的中心化或分布式存储系统中(如IPFS、Amazon S3、阿里云OSS等),区块链上只存储指向这些数据的指针(哈希值或URL)。
- 优点:成本极低,容量几乎没有限制,读写速度快。
- 缺点:安全性依赖于链下存储的可靠性,如果链下数据被篡改或删除,链上的指针就变成了“死链接”,无法验证数据的原始性和完整性。
- 适用场景:大文件、图片、视频、大量文本数据等,如NFT的图片、去中心化应用的用户数据。
典型例子分析
-
比特币:
- :纯交易记录,它是一个极其纯粹的“价值转移”账本。
- 存储策略:所有交易数据都直接写入区块体,是典型的“数据上链”,它不关心你转账的“是什么”,只记录“谁转了多少钱给谁”。
-
以太坊:
- :交易记录、状态变更(账户余额、合约代码变量等)、合约代码本身。
- 存储策略:混合模式。
- 交易和状态:直接写入区块体,是“数据上链”。
- 大文件(如NFT图片):通常采用“链上存哈希,链下存数据”的模式,NFT的智能合约中只存储图片的IPFS地址或其哈希值,图片本身则存储在IPFS等链下存储网络中,这样既保证了NFT所有权的唯一性和可验证性,又避免了高昂的存储费用。
-
Filecoin / Arweave 等存储公链:
- :任何用户想存储的文件。
- 存储策略:专门为“链下存储”而设计,它们通过区块链和代币经济模型来激励全球的存储提供商(矿工)可靠地、永久地保存用户数据,区块链本身记录了数据存储的“订单”和“证明”,确保数据没有被丢失或篡改。
| 特性 | 描述 |
|---|---|
| 基本单位 | 区块,包含区块头(元数据和指纹)和区块体(实际数据)。 |
| 链接方式 | 通过密码学哈希将每个区块链接到前一个,形成不可篡改的链。 |
| 写入机制 | 通过共识机制(如PoW, PoS)由网络共同决定哪个新区块可以被添加到链上。 |
| 核心策略 | 数据上链(安全、昂贵、有限) vs. 数据链下(廉价、无限、依赖外部)。 |
| 最终形态 | 一个去中心化、分布式、不可篡改、可追溯的全球共享数据库。 |
区块链的数据存储是一种在安全、成本和效率之间做出权衡的精巧设计,它并非要取代所有传统数据库,而是在特定场景下(如需要高信任度、防篡改和价值转移)提供了一种革命性的数据存储和验证范式。
文章版权及转载声明
作者:咔咔本文地址:https://www.jits.cn/content/27168.html发布于 02-20
文章转载或复制请以超链接形式并注明出处杰思科技・AI 股讯







还没有评论,来说两句吧...